臨床データマネジメントにおけるAI:何ができるのか、どのように機能するのか?

AI(人工知能)は、臨床試験における実際の課題や問題に対応し、データマネージャーをはじめとする関係者に大きな力を与える技術です。AIは革新的な利点をもたらす一方で、他のテクノロジーとは異なり、ある種の「謎」に包まれており、意見が分かれたり導入の障壁となったりすることがあります。
その背景には、先入観や誤解、利用可能なAIツールへの接触機会の少なさ、そしてAIの仕組みに関する詳細な情報の不足が挙げられます。
本記事では、AIと機械学習(ML)が、メディカルコーディング、データ照合、監査証跡のレビューといった臨床データマネジメント業務において、どのような支援ができるのかを詳しく見ていきます。
AI支援によるメディカルコーディング
臨床試験において、副作用に関連する症状、処置、薬剤の記述や、既往歴、併用薬に関する情報は、逐語表現(verbatims)として記録されます。これらの逐語表現が記録された後、スポンサー企業はFDAおよび他の規制当局の要件に従い、それらを業界標準の辞書に基づいてコード化する必要があります。
図1には、副作用や既往歴のコーディングに使用される MedDRA(医薬規制用語辞書)、および併用薬のコーディングに使用される WHODrug(WHO医薬品辞書) の例が示されています。
たとえば、ある患者の副作用が「headache(頭痛)」として記録された場合、その患者の背景情報や試験の文脈に応じて、MedDRA辞書に基づき「throbbing headache(ズキズキする頭痛)」とされ、コード「10058140」が付けられることがあります。また、別の患者が「paracetamol(パラセタモール)」を服用していた場合、WHODrug辞書に従ってコード「000200」が割り当てられます。
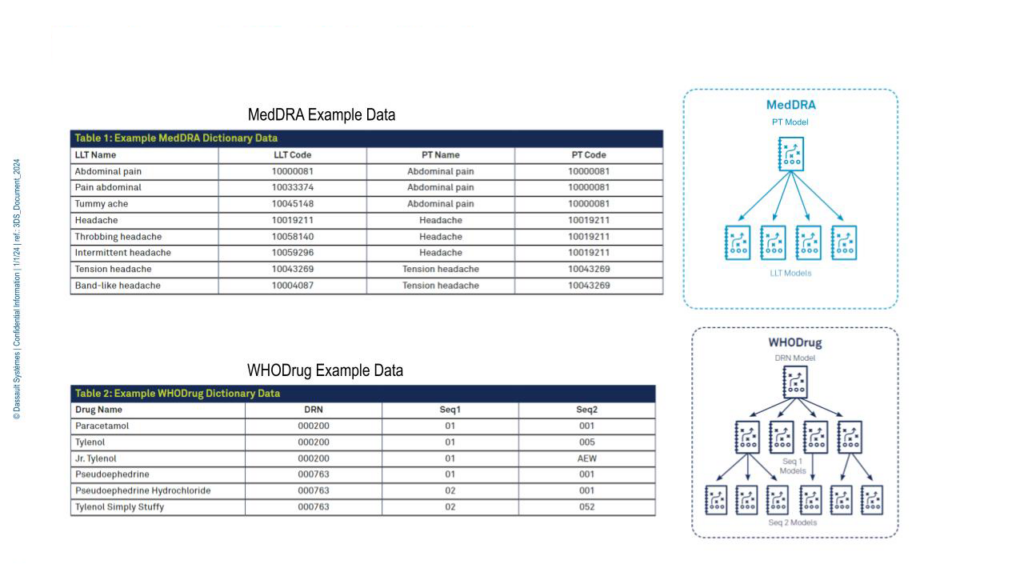
図1.MedDRAおよびWHODrugの例示データ
臨床試験の実施中、メディカルコーダーは何千もの用語をコーディングする必要があり、そのために多くの年数をかけて専門知識を蓄積し、コーディング作業を効率化するための独自の同義語リストを作成・管理してきました。このような複雑で時間のかかる作業を支援・変革する強力なツールが提示されると、その可能性に期待が集まる一方で、ツールの性能、正確性、効率性に対する疑問や関心も同時に生まれます。
機械学習アルゴリズムは、コーディング担当者による同義語リストの保守作業を不要にし、手作業による「検索とコーディング」プロセスにかかる時間と労力を大幅に削減します。
基盤として、メディデータの予測コーディング用機械学習アルゴリズムは、これまでに専門のメディカルコーダーが行った6,000万件以上の逐語用語のコーディング判断をもとに学習・検証されています。対象となる用語は、薬剤名、症状、処置などであり、MedDRAに関する3,000万件超、WHODrugに関する3,000万件超が含まれています。また、これらのデータは、数千件の試験で使用された複数バージョンの辞書を網羅しています。
アルゴリズムに逐語用語が提示されると、その用語がどの辞書コードに対応するかを予測します。そして、メディカルコーダーにはその予測に対する信頼度(高・中・低)が提示されます。これにより、従来必要だった同義語の参照や時間のかかる辞書検索を最初のステップとして行う必要がなくなります。コーダーは、アルゴリズムが提示したコードに対して、「正しい」と判断すればそのままコード化(アルゴリズムに“賛成”)、もしくは「異なる」と判断すれば修正(“反対”)することができます。また、設定された信頼度のしきい値を満たす用語については「自動コーディング」を適用することも可能で、これによりコーディング作業のさらなる効率化が図れます。
予測モデルの開発
過去のコーディング判断を予測モデルの構築に使用する前に、まずデータのクレンジングが行われます。具体的には、逐語表現およびメディカルコードの標準化、辞書からの情報による補強、使用中止となったコードの除外などが実施されます。
データセットは、時系列に基づく方法で「学習用」と「テスト用」に分割されます。古いデータが学習用に、新しいデータがテスト用に使用され、学習データで予測モデルを構築し、テストデータでモデルの性能を評価します。
WHODrugおよびMedDRAのコードは階層構造を持つため、メディデータのMLモデルも階層的構造を採用しています。たとえば、MedDRAであればPT(Preferred Term)、WHODrugであればDRN(Drug Record Number)といった親レベルのコードを予測するモデルを構築し、それぞれの親コードに対して個別の下位レベルモデルも作成されます。モデルは逐語テキストのみを学習対象としており、用語がどのユーザーや試験から発生したものであっても、一貫して同じ予測コードを返す設計となっています。
さらに、モデルは定期的に最新のデータで「更新」されており、最新のコーディング判断に基づいて構築され、新しい辞書バージョンにも対応可能です。
AI支援によるメディカルコーディング ― 精度と効率性
予測コーディングは、逐語をコーディングする際の検索・照合にかかる時間を大幅に短縮しますが、その精度はどの程度なのでしょうか?
ユーザーが高い信頼度のしきい値を選択した場合、MedDRAにおける予測の精度は96%、WHODrugでは92%と、熟練のコーダーによる判断と比較して高い一致率が期待されています。この精度の差は、MedDRAでは1つのコードを選択するだけで済むのに対し、WHODrugではAIが薬剤コードを予測しても、ユーザーがさらにATCコード(解剖治療化学分類)を選択する必要があるためです。
中程度および低信頼度レベルの予測精度は若干低くなりますが、その分自動コーディング可能な逐語の数が増加するという利点があります。
従来の辞書による「検索と照合」手法では、1つの逐語をコーディングするのに平均5分かかるのに対し、AI予測を活用すれば数秒で処理が可能です。臨床試験では数千件もの逐語が存在するため、AIによる自動コーディングによって、試験あたり数十時間〜数百時間もの作業時間を削減できる可能性があります。たとえば、1,000件の逐語を高信頼度で自動コーディングする場合、最大69時間の工数削減が見込まれます。また、すべての逐語に対して予測が生成されるため、自動化されなかった用語であっても、予測を参考にした手動コーディングにより作業時間を大幅に短縮したという報告もあります。さらに、予測・コーディングされた用語はすぐにデータレビューや安全性システムに連携できるため、二重入力や重複作業の削減といった下流工程でのメリットも得られます。
データ照合におけるAIの活用
異なるデータセット間でのデータ照合は、AIが理想的な仮想アシスタントとしての役割を果たす代表的なユースケースです。AIは、手作業で行われていた煩雑な作業を自動化し、業務効率と革新性の向上を実現します。
ナレッジベース型アーキテクチャで構築されたAIエキスパートシステムは、副作用、併用薬、既往歴データセット間の複雑な関連性を評価・ランク付けし、過去の臨床試験データやオープンソースのモデル、辞書などを活用して、各関連性に信頼度を付与することができます。
AIによるデータ照合はアルゴリズム駆動であるため、従来手作業で多くの時間を要していたリストレビュー作業の負担を大幅に軽減し、複雑なデータ品質チェックに対する人的な監視負荷を削減することで、リスクの少ないデータマネジメントが可能になります。また、これまで見逃されがちだった項目も、AIと自動化の力によって高確率で検出されるようになります。
たとえば、「併用薬のない副作用」を検出するレポートを実行した場合、システムはAEとCMの関連性に関するナレッジグラフを参照し、データセット間の潜在的な不整合を特定し、それらを修正するために必要な関連づけの提案を行います。このレポートには、ユーザーが確認すべき提案がリスト化されており、前述のメディカルコーディングと同様に、「賛成/反対」の判定プロセスで処理できます。この人間の関与を含むプロセスによって、エキスパートシステムはさらに学習・進化していきます。
AI支援によるデータ照合により、データマネージャーはもはや、複数のリストを手作業で見比べながら不整合を探す必要はなくなるのです。
Audit Trail Review (ATR)
臨床試験における監査証跡は膨大な情報を含んでおり、治験のあらゆる側面——臨床データ、クエリ、システムログ、アクティビティログ、メタデータ、その他さまざまな情報——を記録しています。これらの証跡は通常、複数のシステムやプロセスにまたがっており、監査証跡レポートを抽出する作業は非常に困難です。たとえデータが集中管理されていても、その解析には負荷がかかり、規制当局からの問い合わせに対応するには多大な時間と労力を要するのが実情です。
こうした課題に対応するため、メディデータは生成AIを活用した監査ログ解析機能の開発を進めています。これにより、データ変更の背景やイベントの時系列を理解・可視化しやすくなり、トレンドの把握や報告作成も容易になります。ユーザーは、スマートプロンプトやチャット機能を通じて簡単にATR結果を取得でき、操作体験も大幅に簡素化されます。
このシステムは、データライフサイクル全体にわたってデータの完全性を担保する管理機能を備えており、関係者に対して透明性・正確性・信頼性の高いATRの提供を可能にします。その結果、規制当局からの質問にも迅速かつ的確に対応することができます。
なお、生成AIの精度を保つためには、偏りのない適切なデータと、適切なプロンプトによる問い合わせが重要な鍵となります。
AI導入への不安と障壁を乗り越えるには
AIによる変革は、一度受け入れられれば、臨床試験をまったく新しい次元へと引き上げる力を持っています。
しかし、導入にあたっては、一部のステークホルダーから戸惑いや懸念の声が上がることもあります。自分の役割がどのように変化するのか、あるいはAIによって役割が統合されたり、置き換えられたりするのではないかといった不安です。こうした反応の多くは、憶測や先入観、誤解に基づいており、前進するためには、AI/MLが「何をするのか」「どう機能するのか」そして「どのようにユーザーの業務や臨床試験、患者の生活を前向きに変革できるのか」について、ステークホルダーが正しく理解できるよう支援することが重要です。
そのためのアプローチとして、私たちは「4つの柱」に基づいたスキル強化(アップスキリング)を推奨しています。
- リテラシーの向上
AIに関する理解と知識を高めるために、チームには以下を提供します:
-
AI学習プログラムおよびナレッジベースの基盤整備
-
具体的な事例を用いたインタラクティブな学習機会
-
AIが反復的な進化プロセスであるという理解
-
新たなビジネス活用事例を見出し、進化を支える仕組み
- 臨床データマネージャーの関与
臨床データマネジメントチームが、AI活用における主導権を感じられるようにするために、以下を徹底します:
-
フィードバックに対する期待値を明確にする
-
AIのフィードバックループがもたらす影響を理解してもらう
-
メリットと限界を正しく伝える(例:不十分または質の低いデータ、バイアス)
- 変革の管理
AIを成功裏に導入するためには、以下に重点を置きます:
-
マインドセットの変革
-
未知への不安や雇用喪失への懸念の払拭
-
トレーニングを通じた安心感の醸成
-
社内の推進役(チャンピオン)を選定し、信頼感を構築
- バリデーション
AIにおけるバイアスのリスクを最小限に抑えるために、以下を実施します:
-
人の関与による判定の重要性を強調
-
複数のデータサブセットにまたがる検証
-
感度分析の実施
-
Real-World Evidenceを活用した検証
-
規制当局との連携
まとめ
ここまで紹介してきた事例からもわかるように、AIはメディカルコーディング、データ照合、監査証跡の処理といった、時間と労力のかかる複雑なデータマネジメント業務を自動化することで、臨床データマネージャーの業務を支援します。これにより、彼らは自身のスキルや経験、専門知識を活かして、解析に必要な高品質データの提供に集中できるようになります。
この考え方は、臨床試験全体の業務領域にも当てはまります。AIは最も複雑で時間のかかるタスクを担うことで、人々の働き方を変革し、臨床試験そのものの進化をまったく新しいレベルへと引き上げる可能性を持っています。
AIの影響が臨床試験業界において今後も変革的であることは広く認識されていますが、それと同時に、AIは誤解されやすく、不安や疑念、恐れさえも生み出す技術でもあります。すべての人がAIの力を最大限に活用できるようにするためには、透明性、包摂性、教育、そして実体験が、成功する導入の土台となります。
これにより、ステークホルダーは、自分の役割、臨床試験、そして患者の生活を前向きに変革する力を手に入れ、新たな専門性と差別化されたスキルセットを身につけることができます。
AI ― それはすべての人のビジネスです。
ホワイトペーパー「Accelerate Precise Medical Coding in Clinical Trials(臨床試験における正確なメディカルコーディングを加速する)」をお読みいただき、Rave Coder+ に搭載されたAIコーディングアルゴリズムの詳細をご確認ください。
また、Medidata Clinical Data Studio が、AI・自動化・スマートアナリティクスを活用し、複数のデータソースを統合・解析することで、レビュー期間の短縮とデータの信頼性向上を実現しながら、包括的なデータマネジメントおよび品質管理の体験をどのように提供しているかをご覧ください。

Contact Us
