Modernizing Clinical Data Transformation to Accelerate Study Close and Kick-start Analysis

Clinical data transformation is a key process to enable the analysis of clinical trial data. Transformed data powers both single and cross-study analyses. In addition, it also unlocks the ability to use historical trial data to generate an external control group or Synthetic Control Arm® (SCA®) in new studies—replacing the need to recruit patients into a randomized control arm using the ‘standard of care’ treatment.
Traditional “batch-processing” data transformation methods require significant time and effort to set up and data is not readily available during study conduct. Batch-processing of data has become highly inefficient in the face of modern complex clinical trials. Such trials are collecting more and more e-sourced, high-volume, and high-velocity data—typically from a variety of devices and sensors that can collect multiple data points per second. To modernize clinical data transformation, the ability to ingest high-volume, high-velocity data is required.
Clinical data is typically stored in disconnected silos using multiple data standards and naming conventions. As a result, there is limited data interoperability of raw data. To create data interoperability, AI/ML-assisted workflows are needed to automate the assignment of semantic meaning and data processing and derivation rules for the numerous data sources. In addition, AI/ML technologies can intelligently identify new variables to create for analytics based on data collected in a trial. However, human-in-the-loop capabilities are also required to confirm suggested semantic meaning assignments. Examples include:
- attributing semantic meaning such as “systolic blood pressure” to designated fields, such as SBP or Sys BP;
- attribute semantic meaning to values, e.g. recoding gender values that may be designated as “M” or “F” or “1” or “2” to “Male” or “Female”; and
- deriving new variables, such as average blood pressure per month, from multiple values over time in the dataset.
The final key to modernizing clinical data transformation is the ability to transform data in near real-time. Streaming technologies are required to apply transformation instructions while the data is being ingested.
Automated and intelligent data transformation processes let you focus on the implications of your data and analyses rather than wasting time and resources on the nuances of standardizing disparate clinical datasets. The results are faster database locks and the ability to reuse data, such as to create external control arms or to kick-start clinical analysis whenever you choose.
The illustration below depicts the major differences between the traditional and modern approaches to data transformation.
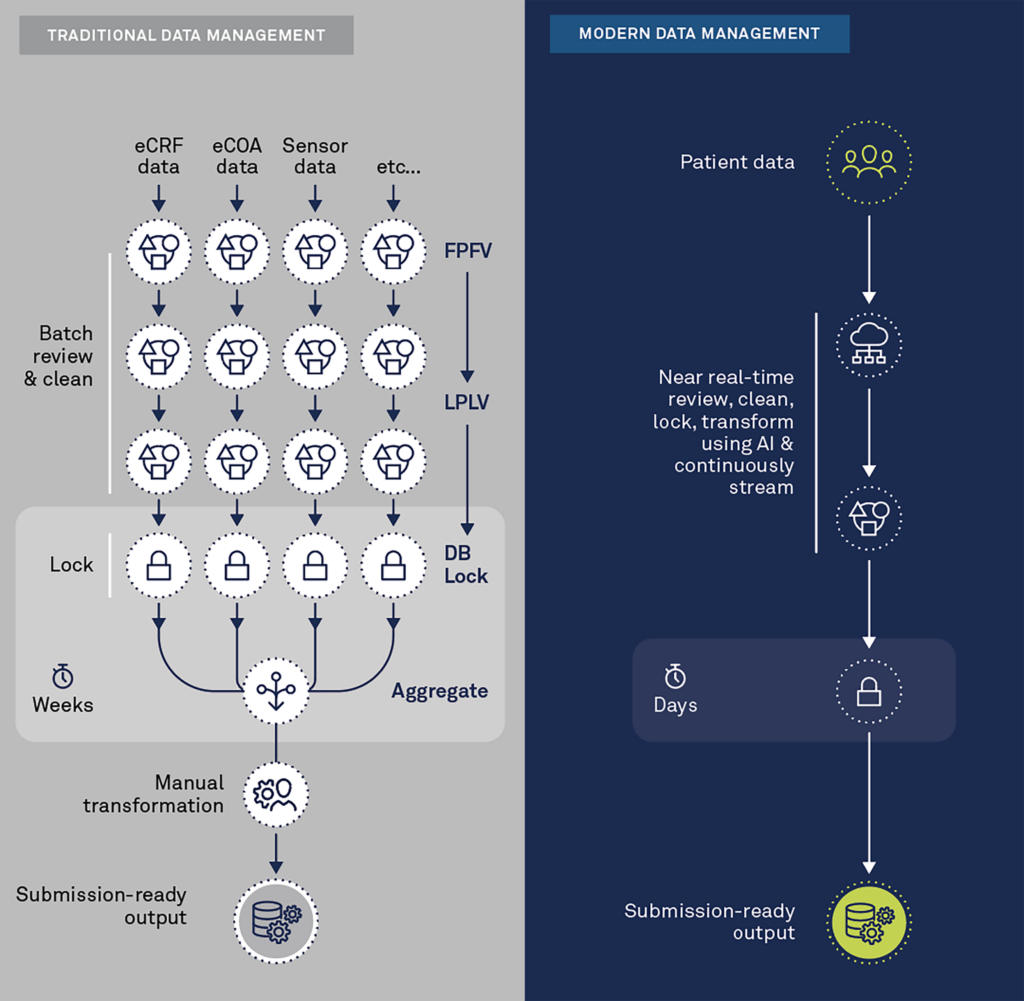
Modern clinical data management platforms seamlessly aggregate data in near real-time. They process and inspect the data via remote digital tools with automated and intelligent algorithms to detect anomalies, inconsistencies, and patterns that should be questioned across all sources (EDC, eCOA/ePRO, Sensors, Imaging, etc.). They also leverage the semantic meaning of the data to automate transformation to standardized, submission-ready output or for other purposes, such as cross-study analysis or synthetic control arms.
Summary
The future of clinical data transformation is here, and it is intelligent, automated, and occurs in near real-time. Today’s clinical trials increasingly rely on high-velocity, high-volume, patient-centric data that are often in different formats. Old-fashioned and manual approaches are inefficient. By transforming data in almost real-time—rather than in batches or at study close—you can achieve faster database locks and start analysis sooner so your clinical trials can deliver results faster.
Download our white paper to learn how to succeed in an increasingly complex clinical trial world:

Author: Gary Luck
Contact Us
